Are the number of applications in your enterprise growing at an unprecedented rate? Is the unstructured data from these apps and other external sources growing exponentially? Is this data easily understandable and searchable for your knowledge workers?
Are you able to extract value from this data or does it end up in a bottomless pit of dark data?
If this sounds like your situation, don’t worry – you’re not alone.
IDC projects that 80 percent of worldwide data will be unstructured by 2025. Unstructured data is being generated rapidly across multiple systems and exists in different formats (PDFs, images, audio, spreadsheets etc.). While organizations recognize the value of this data, they have a hard time exploring, understanding and organizing it. As a result, this data ends up being unsearchable over time and becomes dark data.
This poses four critical problems:
- Decreased productivity of knowledge workers: An IDC report says that knowledge workers spend an average of 2.5 hours every week finding the information they need within their enterprises. This translates into over 30% of the total time each employee puts into work. That is 30% of the time NOT spent on completing their actual work. For a large enterprise, this is equivalent to millions of dollars lost due to reduced productivity.
- Underutilization of data: Usage of data insights across functions is becoming increasingly critical to take accurate business decisions, gain competitive edge and ensure business growth. If business leaders can’t access and tap the potential of unstructured data, companies are sure to lose their relevance, market share and go out of business.
- Compliance Risks: Dark data can also contain huge amounts of Personally Identifiable Information (PII). If this data is not illuminated and discovered, companies can run into the risk of compliance violations and subject themselves to hefty fines of regulatory authorities.
- Ineffective Enterprise Search: If unstructured documents and files are not organized and tagged properly, they won’t show up in search results. Thereby, enterprise search shows not-so-relevant results and loses adoption over time.
Manual Approaches To Knowledge Mining Are Expensive And Error-Prone
Despite realizing the significance of unstructured data, many companies are using manual knowledge mining methods to understand and organize it.
The key prerequisite to effective knowledge management and information findability through search is classifying and tagging the documents accurately using metadata. Metadata refers to information about information – content which describes a particular document.

In a manual environment, the process of reading, understanding and classifying data is heavily dependent on humans. A Hoovers report estimates that the average cost of manually tagging one item runs from $4 to $7.
And in addition, this human-heavy process is error-prone, and often results in mis-tagged content (no two humans comprehend content in a similar way). IDC estimates that it costs you $180 to recreate a document that is not tagged correctly and can’t be found.
For large enterprises this translates to millions of dollars and immense loss of productivity.
With the growing volumes of unstructured data, this approach also poses scalability challenges.
The approach is time-consuming as well. By the time, the information is identified and classified, it loses its value and is fit for only archiving.
How AI-Powered Knowledge Mining Looks Like In Action
Organizing unstructured data and making dark data discoverable has become so much easier with the rise of Artificial Intelligence (AI). Using advanced Machine Learning (ML) techniques, AI bots can automate manual tasks involved in knowledge mining. They crawl through all your documents, understand them, generate metadata, classify and tag them automatically. AI bots tag your documents accurately, at lower overall cost, and at higher speed. Consequently, these documents become easily discoverable through enterprise search.
Since the same bot interprets all your content there will be consistency in the document classification process. AI bots not only tag your documents but also transforms your taxonomy into a living and breathing entity that automatically evolves along with your enterprise.
Learn More:
AI-Powered Knowledge Mining Offers Extensive Business Benefits
While AI-Powered knowledge mining offers several benefits for various industries, it’s critical for businesses which generate huge amounts of data – CPG, retail, finance, healthcare, manufacturing etc.
Some key benefits include:
- Reduced operational and compliance costs
- Increased competitive advantage
- Improved productivity by enabling knowledge workers to focus on their core business activities instead of searching for information
- Improved decision making by making dark data searchable and increasing access to unstructured data
- Improved compliance through easy access and filtering of sensitive information
- Reduced duplication of data
- Powerful enterprise search
Knowledge Mining and Cognitive Search Using The Best of Microsoft Technologies
As a Microsoft Gold Partner, Acuvate uses Microsoft Azure Cognitive Search combined with Microsoft Cognitive Services for AI-powered knowledge mining and delivering advanced search experiences through Mesh 3.0 – World’s First Autonomous Intranet built on SharePoint.
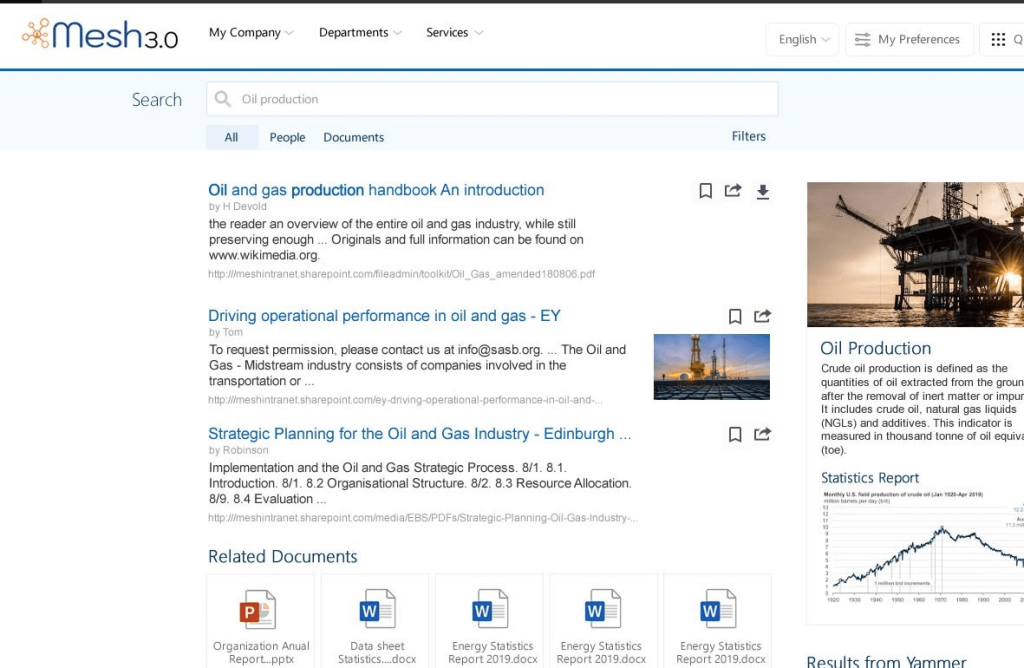
Mesh 3.0 connects all your internal and external enterprise systems including Office 365 and acts as a “one stop cognitive search” for your organization. Based on users’ activities, role, locations and interests it also provides AI-generated tags to enhance the search experience and deliver the right information to the right person
If you’d like to learn more about this topic, please feel free to get in touch with one of our knowledge mining and digital workplace experts for a personalized consultation. If you’re interested to see Mesh in action, we’ll be glad to show you a quick demo.